

mt4平台下载中文使用 cld3检测页面的语言Facebook刚才开源众语种呆板翻译模子「M2M-100」,这边谷歌也来了。谷歌揭晓,基于T5的mT5众发言模子正式开源,最大模子130亿参数,与Facebook的M2M比拟,参数少了,并且支柱更众语种。
前几天,Facebook发了一个百种发言互译的模子M2M-100,这边谷歌恐慌了,翻译不过我的老本行啊。
刚才,谷歌也放出了一个名为 mT5的模子,正在一系列英语自然收拾职分上校服了百般SOTA。
你发,我也发,你支柱100种,我支柱101种!(固然众这一种没有众大事理,但魄力上不行输)
mT5是谷歌 T5模子的众语种变体,演练的数据集涵盖了101种发言,蕴涵3亿至130亿个参数,从参数目来看,实在是一个超大模子。
全邦上成编制的发言现正在粗略有7000种,尽管人工智能正在阴谋机视觉、语音识别等范围依然超越了人类,但只限度正在少数几种发言。
念把通用的AI才干,迁徙到一个小语种上,险些相当于从新再来,有点得不偿失。
众发言人工智能模子策画的方向即是筑设一个可能剖判全邦上大个人发言的模子。
众发言人工智能模子能够正在相通的发言之间共享音讯,消浸对数据和资源的依赖,而且应允少样本或零样本研习。跟着模子领域的推广,往往须要更大的数据集。
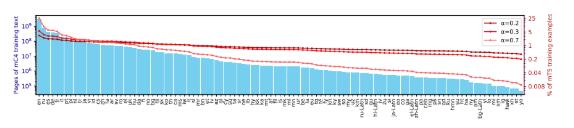
C4是从群众网站得回的大约750gb 的英文文本的聚合,mC4是 C4的一个变体,C4数据集紧要为英语职分策画,mC4搜求了过去71个月的网页数据,涵盖了107种发言,这比 C4应用的源数据要众得众。
固然少许查究职员声称,目前的呆板研习身手难以避免「有毒」的输出,然则谷歌的查究职员连续正在试图减轻 mT5的成睹,譬喻过滤数据中含有过火发言的页面,应用 cld3检测页面的发言,将置信度低于70% 的页面直接删除。
mT5的模子架构和演练历程与T5极端相通,mT5基于T5中的少许方法,譬喻应用GeGLU的非线年),正在较大模子中缩放dmodel而不是dff来对T5举办革新,而且仅对未标志的数据举办预演练而不会产生音讯遗失。
然则,这种抉择是零和博弈:要是对低资源发言的采样过于频仍,则该模子可以会过拟合;要是对高资源发言的演练不敷宽裕,则模子的通用性会受限。
以是,查究团队采用Devlin和Arivazhagan等人应用的手腕,并按照概率p(L) L ^,对资源较少的发言举办采样。个中p(L)是正在预演练时刻从给定发言中采样的概率, L 是该发言中样本的数目,是个超参数,谷歌原委尝试展现取0.3的成果最好。
查究团队为了适当具有大字符集的发言(譬喻中文),应用了0.99999的字符笼罩率,但还启用了SentencePiece的「字节撤退」效力,以确保能够独一编码任何字符串。
为了让结果更直观,查究职员与现有的大领域众发言预演练发言模子举办了扼要对照,紧要是支柱数十种发言的模子。
截至2020年10月,尝试中最大 mT5模子具有130亿个参数,高出了总共测试基准,包含来自 XTREME 众发言基准测试的5个职分,涵盖14种发言的 XNLI 衍生职分,诀别有10种、7种和11种发言的 XQuAD、 MLQA 和 TyDi QA/阅读剖判基准测试,以及有7种发言的 PAWS-X 释义识别。
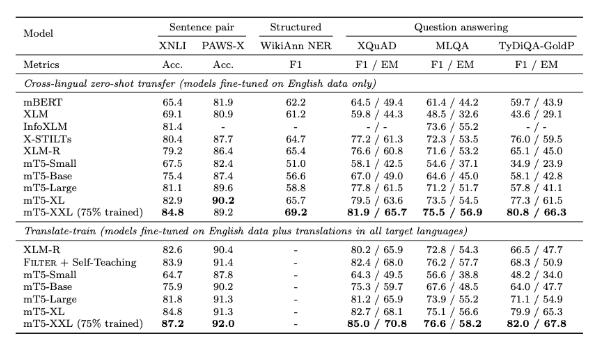
尝试结果能够看到,正在阅读剖判、呆板问答等各项基准测试中mT5模子都优于之前的预演练发言模子。
对预演练发言模子最直白的测试手腕即是怒放域问答,看演练后的模子能否解答没睹过的新题目,目前来看,纵使强如GPT-3,也时常答非所问。
然则谷歌的查究职员断言,mT5是向效力宏大的模子迈出的一步,而这些模子不须要丰富的筑模身手。
总的来说,mT5映现出了跨发言外征研习中的苛重性,并外清晰通过过滤、并行数据或其他少许调优方法,完成跨发言才干迁徙是可行的。
逐日头条、业界资讯、热门资讯、八卦爆料,全天跟踪微博播报。百般爆料、黑幕、花边、资讯一扫而光。百万互联网粉丝互动参预,TechWeb官方微博等待您的体贴。









 关注微信
关注微信